Explore how PCIe 6.0 bandwidth and CXL memory pooling are revolutionizing data center architecture through low-latency CPU-GPU interconnects and shared RAM.
The Unified Memory Revolution: PCIe 6.0 and CXL Architecture
The landscape of the modern data center is undergoing its most significant transformation since the invention of the virtualization layer. As we move through 2026, the traditional "server-as-a-box" model is dissolving, replaced by a composable, disaggregated architecture. At the heart of this shift are two symbiotic technologies: PCIe 6.0 bandwidth and CXL (Compute Express Link). Together, they are solving the "memory wall" that has long throttled AI and High-Performance Computing (HPC) by creating a future where memory is no longer a localized peripheral, but a shared, global resource.
The Infrastructure Crisis: Why We Need a New Model
For decades, data centers have been built on a rigid, siloed architecture. A server's resources—its CPU, GPU, and RAM—were physically and logically locked within a single chassis. This led to two massive inefficiencies:
- Stranded Resources: One server might be using 100% of its CPU but only 10% of its RAM, while a neighboring server sits idle with unused memory that cannot be shared.
- The Memory Bottleneck: As CPU core counts exploded, the parallel DDR interface could not keep up with the required pin density and signal integrity.
CXL (Compute Express Link) was designed to shatter these silos. By running a specialized set of protocols over the standard PCIe physical layer, CXL allows for a CPU-GPU interconnect that treats external devices as if they were internal, cache-coherent components.
PCIe 6.0: The High-Speed Foundation
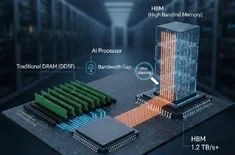
The transition to PCIe 6.0 bandwidth is the "engine" making this new architecture possible. PCIe 6.0 doubles the throughput of its predecessor, reaching a staggering 64 GT/s per lane (up to 256 GB/s for a x16 link).
However, speed is only half the story. PCIe 6.0 introduces several critical innovations that CXL relies on:
- PAM4 Signaling: Moving from binary (0/1) signaling to four-level Pulse Amplitude Modulation (PAM4) allows for doubling the data rate within the same frequency envelope.
- FLIT-based Encoding: Fixed-size Flow Control Units (FLITs) simplify the data link layer, enabling the ultra-low latency reduction required for memory-to-processor communication.
- Low-Latency FEC: A "lightweight" Forward Error Correction (FEC) ensures that the high-speed PAM4 signals remain reliable without the massive latency penalties of traditional error correction.
CXL 3.0: Enabling the Unified Memory Pool
While PCIe provides the wires, CXL (Compute Express Link) provides the language. Specifically, CXL 3.0 (and the newer 3.1/3.2 updates) utilizes three distinct sub-protocols to unify the data center:
- CXL.io: Handles device discovery and non-coherent data transfers (essentially enhanced PCIe).
- CXL.cache: Allows accelerators (GPUs/FPGAs) to cache host memory locally with full hardware-level coherency.
- CXL.mem: Allows the CPU to access memory attached to a device (like a CXL expansion card) as if it were local DRAM.
The Shift to Memory Pooling
The most revolutionary feature of this era is memory pooling. In a CXL-enabled data center architecture, memory is disaggregated into "memory appliances." Instead of each server having its own dedicated (and often wasted) RAM, a cluster of servers can connect to a central pool of memory through a CXL switch.
This doesn't just increase capacity; it fundamentally changes the compute model. Through "multi-headed" devices and fabric-based routing, multiple hosts can now access the same physical memory addresses simultaneously. This is the "Holy Grail" for AI model training, where multi-terabyte datasets can be accessed by an entire fleet of GPUs without the need for constant, redundant data copying over slow network fabrics.
Impact on Data Center Architecture
The adoption of a unified CXL fabric over PCIe 6.0 infrastructure leads to three major shifts in how we build and scale compute:
| Feature | Traditional Architecture | CXL/PCIe 6.0 Architecture |
|---|---|---|
| Memory Access | Local to the motherboard | Global across the fabric |
| Resource Efficiency | Low (Up to 50% stranded RAM) | High (Dynamic allocation from pools) |
| Scalability | Scale-up (Buy bigger servers) | Scale-out (Add memory/compute nodes) |
| Latency | Milliseconds over network (RDMA) | Nanoseconds over CXL |
1. True CPU-GPU Interconnect Coherency
In the past, moving data between a CPU and GPU required "staging" data in system RAM and then copying it via DMA (Direct Memory Access). CXL 3.0 eliminates this. A GPU can now directly "snoop" the CPU's cache and vice versa. This latency reduction is critical for real-time AI inference and large language models (LLMs), where the "KV cache" and model weights can now live in a shared pool accessible by any accelerator in the rack.
2. Composable Infrastructure
Modern data centers are becoming "software-defined" at the hardware level. With CXL fabrics, an orchestrator (like Kubernetes) can "compose" a virtual server for a specific task. If a workload needs 2 CPUs and 2TB of RAM, the system dynamically maps those resources from the pool. Once the task is finished, the 2TB of RAM is released back to the pool for other servers to use.
3. Sustainability and TCO
By reducing "overprovisioning"—the practice of buying more RAM than needed to handle peak loads—CXL significantly lowers the Total Cost of Ownership (TCO). Less physical RAM means lower power consumption, reduced cooling requirements, and a smaller physical footprint. Estimates suggest that memory pooling can improve memory utilization by up to 50%, a massive win for sustainability in the AI era.
The Road Ahead: From PCIe 6.0 to 7.0 and Beyond
As we look toward the end of 2026, the first CXL 3.2 fabric switches are entering production, supporting thousands of nodes in a single coherent domain. While PCIe 6.0 provides the current high-water mark for performance, the roadmap for PCIe 7.0 (128 GT/s) is already being aligned with CXL 4.0.
The future is clear: the era of the "isolated server" is over. We are entering the age of the unified memory fabric, where compute and memory are decoupled, allowing for a level of efficiency and performance that was previously impossible. Whether you are training the next generation of generative AI or managing a hyperscale cloud, the integration of PCIe 6.0 bandwidth and CXL is the foundation upon which the next decade of computing will be built.