Learn how the data lakehouse architecture merges data lakes and warehouses to solve data silos, featuring Delta Lake, real-time analytics
For decades, enterprises have relied on a two-tier architecture. On one side, data warehousing provided the backbone for structured reporting and BI. These systems are highly optimized for SQL queries but are often rigid, expensive, and unable to handle unstructured data like video, audio, or real-time logs.
On the other side, companies built data lakes to store vast amounts of raw data at a low cost. While excellent for data science and ML, these lakes often turned into "data swamps" due to a lack of governance, poor query performance, and the absence of transactional integrity.
The Consequences of Disconnected Systems
When BI and AI live in separate houses, the data silos problem manifests in several ways:
- Inconsistency: Metrics calculated in the warehouse often don't match those in the data lake.
- Latency: Data must be moved and transformed (ETL) between systems, delaying insights.
- High Costs: Maintaining two infrastructures, two security models, and two sets of data duplicates is a drain on resources.
- Governance Gaps: Managing privacy and compliance across two disparate environments is a regulatory nightmare.
What is a Data Lakehouse?
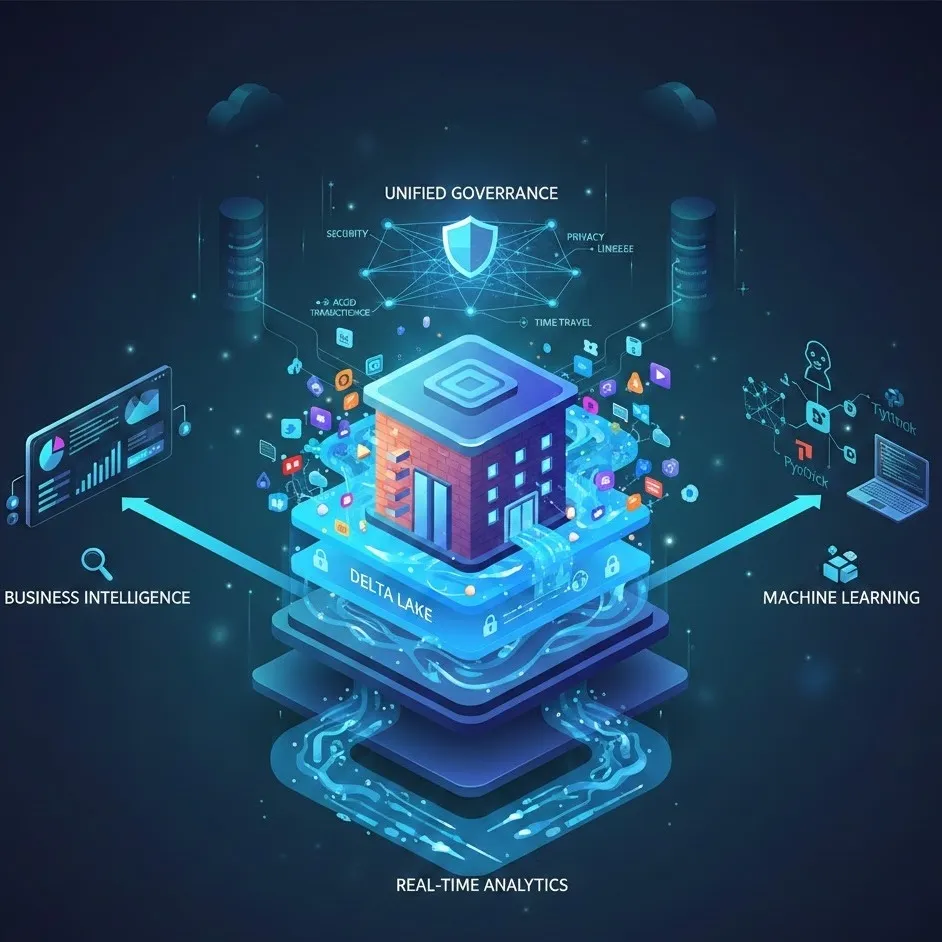
A data lakehouse is a new, open data management architecture that combines the cost-efficiency and flexibility of a data lake with the performance, reliability, and unified governance of a data warehouse. It allows for real-time analytics and advanced AI workloads to run on the same platform where your structured business reports reside.
The Role of Delta Lake
The "magic" that enables a lakehouse is the metadata layer. Delta Lake is a primary example of this technology. It is an open-source storage layer that brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to Apache Spark and big data workloads.
By using Delta Lake, organizations can:
- Enforce Schemas: Prevent "garbage in, garbage out" by ensuring data matches the expected format.
- Enable Time Travel: Access previous versions of data for auditing or rolling back errors.
- Support Upserts: Easily perform updates and deletes on data stored in the lake, which was historically difficult.
Why Data Stack Convergence is the Future
The shift toward data stack convergence isn't just a trend; it's a necessity for the AI-driven enterprise. By merging these layers, organizations unlock several transformative benefits.
1. Unified Governance and Security
In a traditional setup, you have to manage permissions in the warehouse and separately in the S3 or ADLS buckets of your lake. A lakehouse provides unified governance, allowing data stewards to set access controls, track lineage, and manage data quality from a single interface. This ensures that whether a user is accessing data via a Tableau dashboard or a Python notebook, the same security rules apply.
2. High-Performance Real-Time Analytics
Modern businesses can't wait for nightly batch jobs. The lakehouse architecture supports real-time analytics by allowing streaming data to land directly in transactional tables. This means your "Gold" layer tables are always up to date, enabling instantaneous decision-making for fraud detection, supply chain adjustments, or personalized customer experiences.
3. Better Support for Machine Learning
Data scientists no longer need to export data from a warehouse into a flat file to train a model. Because the lakehouse stores data in open formats (like Parquet), ML frameworks like TensorFlow or PyTorch can read the data directly. This direct access accelerates the development lifecycle and ensures models are trained on the most current production data.
4. Reduced Total Cost of Ownership (TCO)
By eliminating the need to move data between a lake and a warehouse, you remove the "ETL tax." You only pay for one storage layer (usually low-cost cloud object storage) and scale your compute resources independently based on the workload.
Architectural Comparison: Warehouse vs. Lake vs. Lakehouse
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Data Types | Structured | All types (Raw) | All types (Structured/Unstructured) |
| Performance | High (SQL) | Low/Moderate | High (SQL & Programmatic) |
| Governance | Robust/Closed | Weak/Manual | Unified Governance (Open) |
| Cost | High | Low | Low (Storage) Flexible (Compute) |
| Workloads | BI & Reporting | Data Science & ML | BI, ML, & Real-time Analytics |
Conclusion: Unlocking the Full Potential of Your Data
The transition from segregated systems to a data lakehouse represents a major milestone in the journey toward a truly data-driven organization. By solving the data silos problem and embracing data stack convergence, businesses can finally provide a seamless environment for both analysts and data scientists.
Whether you are looking to optimize your business intelligence or scale your machine learning initiatives, the combination of Delta Lake and lakehouse architecture provides the reliability, speed, and unified governance required for the modern era.