A decentralized, domain-oriented data architecture treating data as a product. Learn about data governance and scalability.
For decades, the standard approach to managing enterprise data revolved around centralization. Data was extracted from various operational systems, loaded into a massive, monolithic data warehouse or a central data lake, and then served to the business. While this approach provided a single source of truth, it inevitably created bottlenecks, fostered a lack of ownership among business teams, and severely hampered innovation and speed.
In the era of big data, rapid digital transformation, and distributed microservices, this central data model—often managed by a single, overwhelmed IT team—has proven to be the main point of failure for modern analytics. This inefficiency has led to the emergence of the Data Mesh, a revolutionary architectural and organizational paradigm proposed by Zhamak Dehghani. It represents a fundamental shift in how organizations handle, share, and manage their analytical data.
The Data Mesh is a decentralized approach to data architecture where data is treated as an accessible product owned by domain teams, not a central IT team. This core philosophy solves the scaling, ownership, and agility problems inherent in traditional centralized data models.
This architecture is not just about technology; it’s a socio-technical transformation centered on four core principles, which collectively enable true data democratization and scalability.
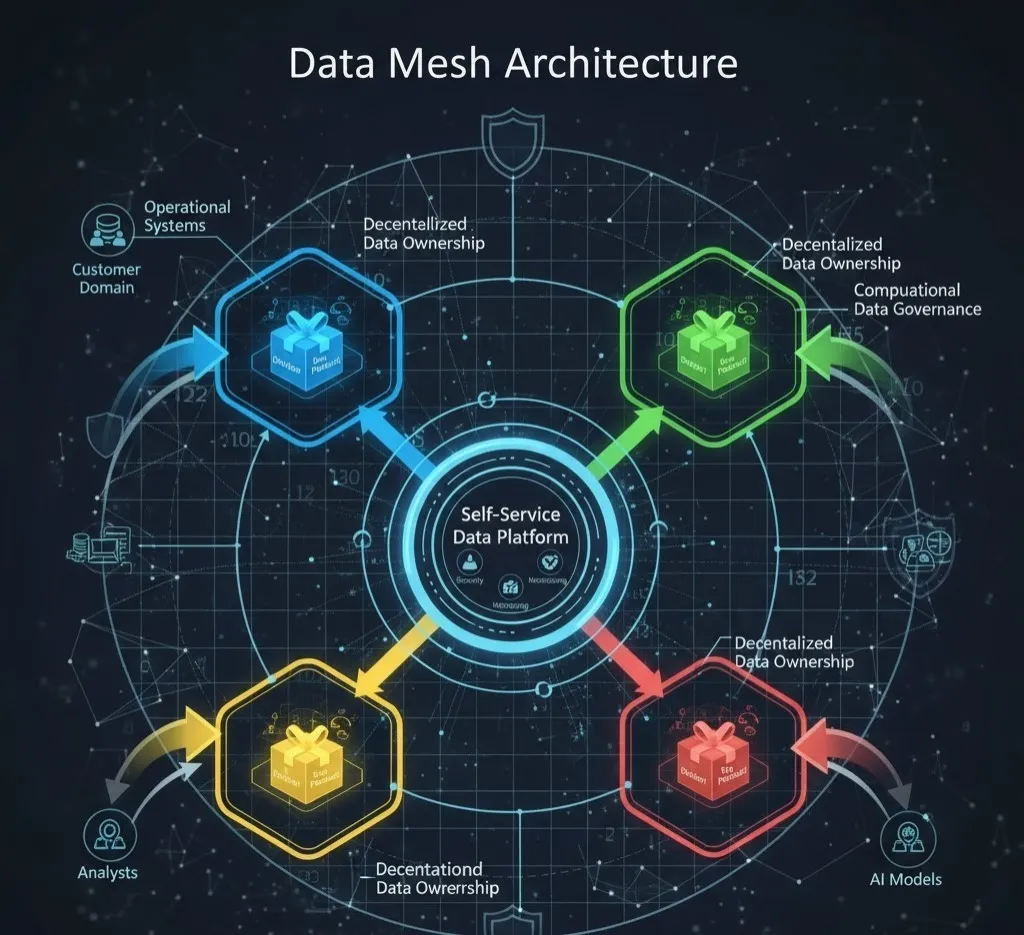
The Four Foundational Principles of Data Mesh
The Data Mesh is built upon four pillars that challenge conventional wisdom regarding data management:
-
Decentralized Data Ownership (Domain-Oriented Data)
The most significant shift the Data Mesh introduces is the concept of decentralized data ownership. Instead of a central team being responsible for all data ingestion, quality, and transformation, the responsibility is delegated to the domain-oriented data teams that intrinsically understand the data best.
Domain-oriented data means organizing the analytical data around business domains—such as "Customer," "Product Inventory," or "Sales Orders"—rather than technical processes (like "ETL Ingestions"). The teams running these operational domains become fully accountable for serving their data to the rest of the organization.
Impact on the Organization: This principle directly links business outcomes to data quality. The Customer domain team, for instance, is far better equipped to define, clean, and enrich the 'Customer' data model than a generalist central data team. This dramatically improves data accuracy and context. It eliminates the "data silo" problem by transforming the silos into owned, accessible data assets.
-
Data as a Product
If business domains own the data, they must treat it like a service they are selling internally. This is the data as a product principle. To qualify as a "product," a dataset must meet the needs of the data consumers. This means the data must be:
- Discoverable: Easy to find and understand via a central catalog.
- Addressable: Accessed via a unique identifier or endpoint.
- Trustworthy & High Quality: Guaranteed by the domain team (e.g., SLAs, quality metrics).
- Self-Describing: Complete with rich metadata, semantics, and clear documentation.
- Secure: Access controlled and compliant with internal policies.
- Interoperable: Standardized formats and access protocols.
By forcing domain teams to adhere to these product characteristics, the Data Mesh ensures that analytical data is inherently reliable, usable, and valuable to data scientists and business analysts. It shifts the mindset from input (ingesting data) to output (delivering value).
-
Self-Service Data Platform
Decentralizing ownership would be chaotic without a common infrastructure layer. The third principle calls for a self-service infrastructure—a foundational, cross-functional data platform that abstracts the complexities of data management.
This platform provides domain teams with the tools and capabilities they need to manage, store, and serve their data as a product without having to build the underlying infrastructure (like storage, security, monitoring, and lineage) from scratch.
Key Capabilities: The platform should offer automated provisioning, standard templates for creating data products, integrated monitoring, and unified security controls. It functions as the "platform-as-a-service" layer, enabling rapid deployment and data governance consistency across all domains. This allows domain data teams to focus on data quality and feature development rather than infrastructure plumbing.
-
Federated Computational Data Governance
With decentralized data ownership, a centralized command-and-control governance model is obsolete. The Data Mesh replaces it with federated computational data governance.
- Federated: Data governance rules and policies are defined collaboratively by representatives from the domain teams and the central governance body. This ensures policies are practical and have buy-in from those who implement them.
- Computational: The policies are enforced through the self-service data platform via automated technical mechanisms (code, configuration, and scripts) rather than manual processes. For example, security policies (like PII masking or access control) are embedded into the data as a product template, ensuring every new data product is compliant by default.
This structure ensures that data remains interoperable, secure, and compliant across the organization while still supporting the speed and autonomy provided by the decentralized architecture.
Data Mesh vs. Traditional Architectures
| Feature | Monolithic Data Warehouse/Lake | Data Mesh Architecture |
|---|---|---|
| Data Ownership | Central IT/Data Team (Single Point of Failure) | Decentralized Data Ownership (Domain Teams) |
| Data Model | Tightly coupled, ETL/ELT-driven, centralized schema | Loosely coupled, Data as a Product, domain-driven schema |
| Architecture Style | Centralized, Monolithic, Batch-heavy | Distributed, Domain-Oriented Data, Microservices-aligned |
| Governance | Centralized, Manual, Policy-driven | Federated Computational Data Governance, Automated |
| Scalability | Hindered by central team bottleneck | Scales linearly with the number of business domains |
The primary differentiator is the resolution of the centralization bottleneck. In a monolithic system, as the business grows, the central data team's backlog grows exponentially, leading to slow data delivery, poor quality, and frustrated business users. The Data Mesh scales the data responsibility along with the business itself, providing an inherent mechanism for achieving organizational agility and data agility.
Benefits of Implementing Data Mesh
The shift to a Data Mesh offers profound organizational and technical advantages:
-
Increased Agility and Speed to Insight
By empowering domain teams to directly publish their data as a product, the dependency on a central data team for every ingestion and transformation is removed. This accelerates the time it takes for a new data source to become a usable analytical insight, allowing the business to react faster to market changes.
-
Improved Data Quality and Trustworthiness
Decentralized data ownership inherently improves data quality. The team that creates the operational data is the same team accountable for the quality of the analytical data product, leading to higher standards, better metadata, and fewer quality issues. This ultimately drives up the trustworthiness of the data.
-
Organizational Scalability
The architecture is inherently scalable. As the company adds new business units or domains, new domain data teams can be spun up without overloading the central data platform team. The platform team’s job becomes managing the infrastructure, not the data content, enabling the entire data ecosystem to scale with the organization.
-
Enhanced Security and Compliance
Through federated computational data governance, security and compliance rules (like GDPR or CCPA requirements) are automated and applied at the product level. This ensures compliance is consistently enforced and baked into the architecture, significantly reducing audit risks compared to manual, centralized enforcement.
Challenges and the Path to Data Mesh Implementation
While the vision of Data Mesh is compelling, its implementation is a significant undertaking that requires tackling cultural and technical challenges.
-
Cultural and Organizational Change
This is the hardest part. Shifting from a centralized IT mindset to decentralized data ownership requires new roles (e.g., Data Product Owner), new skill sets within domain teams, and a willingness from the central IT team to let go of control. Leadership buy-in is crucial to drive this deep organizational transformation.
-
Standardizing Interoperability
For the entire ecosystem to work, data products from different domains must be easily combined and consumed. This requires the federated computational data governance to enforce standard protocols, formats (e.g., using consistent serialization like Apache Avro), and naming conventions across the organization. The self-service platform must provide the tools to enforce these standards.
-
Initial Investment in the Self-Service Platform
Building a robust, enterprise-grade self-service data platform that abstracts away complexity and automatically enforces governance is a significant initial investment. The platform must provide foundational capabilities, including cataloging, security, monitoring, and lineage tracking, for every data product.
The Phased Implementation Strategy
A successful implementation often follows a phased approach:
- Pilot a Domain: Start with one or two well-defined, enthusiastic business domains to define and publish their first data as a product.
- Build the Minimum Viable Platform: Create the basic self-service infrastructure capabilities necessary to support the pilot domains.
- Establish Federated Governance: Define the initial set of standards and computational rules collaboratively with the pilot teams.
- Iterate and Scale: Gradually onboard more domains, using the experience and best practices from the initial rollout to refine the platform and governance model.
The Future of Data Architecture
The Data Mesh is more than an architectural pattern; it is a blueprint for the modern, agile data-driven enterprise. By distributing responsibility and ownership, treating data as a product with clear APIs, and managing the ecosystem with federated computational data governance, organizations can finally escape the bottlenecks of monolithic systems.
For companies grappling with massive data volumes and demanding business users, embracing Data Mesh principles is the critical step toward building a truly scalable, resilient, and business-aligned data architecture that turns data from a burden into a powerful, accessible competitive asset. The future of data is distributed, and the Data Mesh provides the map for that journey.