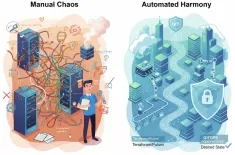
Master Edge AI and TinyML. Learn how energy-efficient chips run on-device models for real-time processing and low latency inference at the edge for IoT.
The rise of Edge AI and TinyML represents a fundamental shift in how artificial intelligence is deployed, moving sophisticated machine learning capabilities out of the centralized data center and directly onto the billions of resource-constrained devices—sensors, microcontrollers, and IoT gadgets—that generate data. This paradigm, known as inference at the edge, is driven by the critical need for speed, privacy, and efficiency in a hyper-connected world.
Defining the Revolution: Edge AI vs. TinyML
While often used interchangeably, Edge AI and TinyML represent two distinct, yet complementary, fields within the broader movement of decentralized intelligence.
Edge AI
Edge AI refers to the umbrella concept of processing data and performing machine learning inference at the edge—meaning close to the data source rather than in a distant cloud server. This includes powerful devices like industrial gateways, autonomous vehicle computers, and high-end security cameras. The primary goals are:
- Real-time processing: Essential for immediate action and decision-making.
- Low latency: Eliminating the round-trip time required to send data to the cloud and wait for a response.
- Privacy: Raw, sensitive data stays local to the device, reducing transmission and storage risks.
TinyML (Tiny Machine Learning)
TinyML is a specialized subset of Edge AI focused on taking this capability to the extreme: running complex machine learning models directly on highly resource-constrained devices, such as microcontrollers (MCUs) that possess only a few hundred kilobytes of memory and operate on ultra-low power.
TinyML's unique challenges and opportunities revolve around:
- Energy-efficient chips: Designing models and hardware specifically for minimal power consumption, often allowing devices to run for months or years on coin-cell batteries or even through energy harvesting.
- On-device models: Creating highly compressed and optimized models that fit within the severely limited RAM and flash memory of MCUs.
The Technical Imperative: Why Move AI to the Edge?
The shift from cloud-centric AI to edge deployment is not a luxury; it is a necessity driven by physical, economic, and ethical constraints.
Eliminating Latency for Real-Time Processing
In many critical applications, milliseconds matter. The round-trip delay from a device transmitting data to the cloud, the cloud processing it, and the cloud sending a response back (often exceeding 100-300 milliseconds) is simply unacceptable.
- Autonomous Systems: For a self-driving car or a factory robot, object detection and collision avoidance must be processed instantly. Edge AI enables real-time processing of sensor data (LiDAR, camera, radar) locally, ensuring low latency for instant decision-making.
- Predictive Maintenance: An industrial sensor detecting an anomalous vibration in a machine needs to trigger an immediate alert to prevent catastrophic failure, a task requiring inference at the edge.
Bandwidth, Cost, and Offline Reliability
The sheer volume of data generated by billions of IoT devices—especially video and high-frequency sensor readings—would overwhelm network infrastructure and incur prohibitive cloud storage and processing costs.
- Bandwidth Efficiency: With Edge AI, the device only sends metadata (e.g., "Motion detected at 10:15 AM" or "Vibration signature changed") to the cloud, not the raw, massive video or sensor stream. This drastically cuts bandwidth use.
- Offline Capability: Devices utilizing TinyML can continue to function and make intelligent decisions even when network connectivity is limited or entirely absent, making them ideal for remote environmental monitoring or deep sea sensors.
Data Privacy and Security
The local nature of on-device models inherently solves major privacy concerns.
- Security: Raw, sensitive data (like biometric data, voice recordings, or private security footage) never leaves the device. This reduces the attack surface and minimizes the risk of mass data breaches during transmission or storage on third-party servers.
- Compliance: This local processing is crucial for complying with strict data protection regulations (like GDPR) where personal data must be managed with high security.
The TinyML Pipeline: Achieving Ultra-Low Power AI
The core challenge of TinyML is fitting a complex neural network onto a processor designed primarily for simple control tasks. This requires an exhaustive optimization pipeline.
Model Design and Optimization
Traditional deep learning models are too large. TinyML employs techniques to drastically shrink the model size while maintaining acceptable accuracy:
- Quantization: This is the process of reducing the precision of the model's weights and activations, typically from 32-bit floating-point numbers down to 8-bit integers. This reduction allows the model to be stored and processed much faster on energy-efficient chips designed for integer arithmetic.
- Pruning and Sparsity: Removing connections or weights in the neural network that contribute minimally to the overall output.
- Efficient Architectures: Using highly specialized, compact neural network architectures (like MobileNet or efficient convolutional networks) designed for minimal computational overhead.
Hardware and Frameworks
Success relies on specialized hardware and software tools:
- Energy-Efficient Chips: Modern microcontrollers often include dedicated hardware accelerators or highly optimized instruction sets to speed up matrix multiplication—the core operation in deep learning—while consuming minimal power (often in the milliwatt or microwatt range).
- Frameworks: Tools like TensorFlow Lite Micro are essential. This is a lightweight version of TensorFlow specifically designed to run on-device models without an operating system, fitting the core runtime into mere kilobytes of memory.
Real-World Applications of Edge AI and TinyML
The combination of Edge AI and TinyML is unlocking new classes of products across every sector.
| Sector | Application | Key Advantage |
|---|---|---|
| Smart Home | Keyword Spotting (e.g., "Hey Alexa") | The device is always-on but listens for the keyword using TinyML on an energy-efficient chip before sending the voice command to the cloud, ensuring low power and privacy. |
| Healthcare | Real-time Heart Monitoring Wearables | On-device models analyze heart rhythm data instantly, detecting anomalies with real-time processing. Sensitive health data never leaves the wearable, ensuring high data privacy. |
| Industrial IoT | Acoustic Monitoring / Predictive Maintenance | Inference at the edge uses TinyML to analyze machine vibrations or acoustic signatures to predict equipment failure hours before it happens, requiring low latency for critical alerts. |
| Agriculture | Crop Pest and Disease Detection | Image classification models run on battery-powered field cameras, detecting pests or soil issues and providing an immediate, localized response without constant Wi-Fi access (offline capability). |