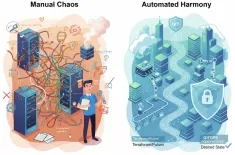
Overcome data scarcity, ensure data privacy preservation, and boost model robustness with digital twins.
The demand for data in the AI era is insatiable. Deep learning models, in particular, require massive and diverse datasets to generalize effectively and avoid brittle performance. However, securing this data is often fraught with obstacles:
- Rarity of Events: In critical safety systems, like autonomous driving or fraud detection, the most important scenarios—accidents, system failures, or fraudulent transactions—are, by definition, rare. Real-world data collection for these edge cases would take decades.
- Cost and Time: Collecting, cleaning, and human-labeling large volumes of real-world data is an immensely expensive and time-consuming process that often delays model deployment.
- Confidentiality and Regulation: Highly sensitive domains like healthcare (HIPAA) and finance (GDPR) face stringent data privacy preservation regulations, making the use of real patient or customer data for AI training a legal and ethical minefield.
- Bias and Fairness: Real-world datasets often contain inherent human biases, which, if left unchecked, lead to discriminatory or unfair AI model outcomes.
Synthetic data generation directly addresses these issues. This process creates new data points—images, text, time series, or tabular data—that mathematically and statistically mirror the properties and patterns of real data, but are entirely artificial and contain no personally identifiable information (PII).
Techniques for Synthetic Data Creation
The methods employed for creating synthetic data vary significantly based on the data type and application domain, ranging from simple rule-based algorithms to sophisticated deep learning architectures.
Rule-Based and Statistical Models
These foundational techniques are suitable for structured, tabular data where the underlying data generation process can be explicitly defined.
- Rule-Based Systems: Data is generated based on a set of predefined logical rules and constraints. For example, in simulating a credit card transaction, rules might govern the valid range for transaction amounts, the velocity of transactions, and known patterns of fraud.
- Monte Carlo Simulation: Used to model complex systems by relying on repeated random sampling to obtain numerical results. It is excellent for modeling uncertainties and generating synthetic financial market data or complex sensor readings with noise.
- Explicit Distribution Modeling: Generating data points by sampling from known probability distributions (e.g., normal, uniform) that have been fitted to the statistical properties of the original real-world data.
Deep Generative Models
The most cutting-edge synthetic data is created using deep learning models that learn the complex, non-linear correlations within the real data.
- Generative Adversarial Networks (GANs): A powerful framework consisting of two neural networks: a Generator that creates synthetic samples and a Discriminator that tries to distinguish between real and fake data. They compete in a zero-sum game until the Generator produces data so realistic the Discriminator can no longer reliably tell the difference. GANs are excellent for generating photorealistic images and complex time-series data.
- Variational Autoencoders (VAEs): These models learn a compressed, latent representation of the input data's underlying probability distribution. The decoder component then samples from this latent space to reconstruct and generate new, similar data points. VAEs are often preferred for their stable training and ability to model complex distributions.
- Large Language Models (LLMs): For textual synthetic data, sophisticated LLMs can be prompted to generate massive amounts of domain-specific, high-quality text, dialogue, or code snippets, often used to train or fine-tune other language models.
Simulation-Based Training and Digital Twins
While purely generative models learn from the patterns in existing data, simulation-based training offers a more direct, physics-informed approach, especially for complex physical systems and environments. This is where the concept of digital twins becomes central.
The Power of Digital Twins
A digital twin is a virtual replica of a physical asset, process, or system. These virtual environments are governed by real-world physics engines and constraints, allowing for the generation of perfectly labeled and photorealistic data by simply observing the virtual world.
- Autonomous Systems: For self-driving cars, drone navigation, and robotics, massive, high-quality labeled datasets are essential. Simulation platforms like NVIDIA's Isaac Sim or CARLA create detailed virtual cities, traffic scenarios, and weather conditions. Within these digital twins, millions of miles of synthetic driving data can be generated—complete with pixel-perfect labels for objects, depth, and semantics—without risking real-world accidents.
- Industrial Applications: In manufacturing, a digital twin of a factory floor can simulate the performance and degradation of machinery. Simulation-based training data—like synthetic sensor readings of a failing bearing or a simulated stress test on an assembly line—is generated to train predictive maintenance models. This allows AI systems to be deployed with unprecedented model robustness before a single real-world failure occurs.
- Controlled Experimentation: The virtual nature of simulation allows developers to inject specific, rare, or extreme conditions (edge cases) repeatedly and systematically, which is impossible or unsafe in the real world. This controlled environment is crucial for exhaustive testing and validation.
Key Advantages and Benefits
The synergy between advanced simulation and synthetic data offers transformative benefits across industries.
Overcoming Data Scarcity
The most immediate and pervasive benefit is the ability to bypass the lack of real data. In fields like aerospace, rare disease research, or advanced robotics, where observations are limited, synthetic data generation provides an endless, tailored, and cost-effective data supply. For instance, in medical imaging, synthetic X-rays or MRIs can augment small, real datasets to create balanced training sets for models detecting rare conditions.
Data Privacy Preservation
This is a monumental advantage, particularly under strict regulations like GDPR. Since synthetic datasets are created *de novo* and do not map back to any single individual's real data, they are inherently privacy-preserving. They maintain the statistical intelligence and structural correlations of the original data while eliminating the risk of exposing sensitive PII. This enables organizations to:
- Share data externally for collaboration without legal risk.
- Accelerate internal data sharing between departments.
- Migrate data to the cloud or use it for public demos safely.
Enhancing Model Robustness and Fairness
Synthetic data gives developers unprecedented control over the dataset's composition, allowing them to explicitly address biases and weaknesses in the real-world data.
- Bias Mitigation: If a facial recognition model's real training data is skewed towards one demographic, synthetic samples of underrepresented groups can be generated to rebalance the dataset, significantly improving the fairness and generalization of the model.
- Edge Case Coverage: By generating extreme, but plausible, scenarios through simulation-based training, the AI model is exposed to conditions it would never see in routine real-world operation. This exposure is vital for enhancing model robustness, ensuring the AI system remains reliable and safe even under adverse or rare circumstances.
Challenges and The Road Ahead
Despite its profound potential, synthetic data is not a silver bullet. Its effectiveness hinges on fidelity and transferability.
The Domain Gap
The primary challenge is the domain gap (or sim2real gap), which refers to the discrepancy between the synthetic environment and the real world. If the synthetic data is not sufficiently realistic—if the generative model overfits the original data, or if the simulation physics are slightly off—models trained solely on it may exhibit poor performance when deployed in the real world. Overcoming this requires:
- High-Fidelity Generators: Developing more sophisticated GANs and VAEs capable of capturing subtle, high-order correlations.
- Sim2Real Transfer Learning: Employing domain adaptation techniques to bridge the gap, such as training the model with a small amount of real data alongside the large synthetic dataset.
Fidelity and Validation
The utility of synthetic data is only as good as its fidelity to the real data. Rigorous validation is essential to ensure that the generated data accurately preserves the statistical properties, correlations, and predictive power of the original dataset. Validation methods often involve running the same analytical models on both real and synthetic data and comparing the resulting metrics (e.g., $R^2$ scores, F1 scores, or key performance indicators).
The Ethical Horizon
As synthetic data becomes more realistic, new ethical questions arise, particularly around its potential use in generating deepfakes or misinformation. Furthermore, if the generation models are trained on biased real data, the synthetic data can unintentionally amplify those biases if not carefully controlled. Ethical AI frameworks and governance over synthetic data generation are becoming crucial research areas.
Conclusion: The Future of AI is Synthetic
Advanced Simulation and Synthetic Data mark an inflection point in the AI lifecycle. By moving beyond the limitations of purely real-world data, organizations can unlock unprecedented speed, control, and privacy in their AI development pipelines. The strategic deployment of digital twins and advanced synthetic data generation techniques addresses the critical issues of data scarcity and data privacy preservation, fundamentally accelerating the path to market for complex, safety-critical AI applications. The result is a new generation of AI models characterized by superior model robustness, enhanced fairness, and the ability to confidently navigate the most challenging and rare real-world scenarios. Synthetic data is not just an alternative; it is the scalable, secure, and future-proof foundation upon which the world's most sophisticated and ethical AI systems will be built.